Google ha anunciado que va a comenzar a incluir documentos escaneados en sus resultados de búsqueda, una verdadera hazaña. Ya que a diferencia de los documentos de texto estándar, los archivos escaneados no contienen datos de texto que las arañas de Google puedan indexar. En su lugar, Google debe emplear un procedimiento llamado Reconocimiento óptico de caracteres (o también llamado OCR), tecnología que convierte las palabras de fotos digitales en texto plano.
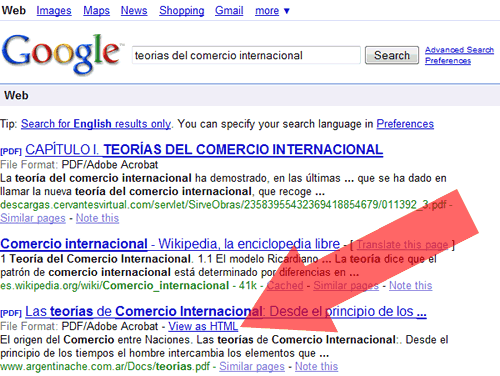
Con este nuevo método, los documentos PDF aparecerán directamente enlazados en el buscador, sin poner en riesgo la calidad de sus búsquedas. Pues, si bien es cierto, desde hace mucho Google ofrece PDFs en su buscador, siempre basaba estas búsquedas en base a metadatos cercanos al documento. Ahora, en cambio, cada vez que veamos un documento como PDF, también tendremos la opción de verlo como HTML.
En la imagen de encima pueden ver como quedarán los resultados con los documentos PDF escaneados y su enlace para verlo como HTML.
Fuente | Google blog
Si te gustó este artículo también te gustará...






